次の\(2\)つの条件\(\mathrm{(i),(ii)}\)をみたす自然数\(n\)について考える.
\(\mathrm{(i)}~\)\(n\)は素数ではない.
\(\mathrm{(ii)}~\)\(l,m\)を\(1\)でも\(n\)でもない\(n\)の正の約数とすると,必ず\[|l-m|\leq 2\]である.このとき,次の問いに答えよ.
-
- \(n\)が偶数のとき,\(\mathrm{(i),(ii)}\)をみたす\(n\)をすべて求めよ.
- \(n\)が\(7\)の倍数のとき,\(\mathrm{(i),(ii)}\)をみたす\(n\)をすべて求めよ.
- \(2\leq n \leq 1000\)の範囲で,\(\mathrm{(i),(ii)}\)をみたす\(n\)をすべて求めよ.
(大阪大)
うーんわからない/(^o^)\
なんかよくわからないので,実験してみます。
(考え方)
\(\textbf{1.}\)
偶数\(2,4,6,8,\cdots\)を順に調べてみます。

するとどうやら,\(n\)が\(10\)以降だと適するものが現れないのでは?と予想できます。そこで,「\(n\geq 10\)ならば\(n\)は\(\mathrm{(i),(ii)}\)を満たさない」という命題の証明を試みます。実際,\(n=2k~(k\geq 5)\)とおくと,\(2\)と\(k\)は\(n(=2k)\)の\(1\)でも\(n\)でもない正の約数ですが,\[|k-2|=k-2\geq 5-2 =3\]となり\((\mathrm{ii})\)を満たしません。
これで\(1.\)の答えは\(4,6,8\)のみであることが分かりました。
\(\textbf{2.}\)
これも\(1.\)と同様に考えてみます。ただし\(n\)が偶数の場合は\(1.\)ですでに調べているので,これを除いて調べていきます:

すると\(n\)が\(63\)以降だと適するものが現れないのでは?と予想できます。そこで「\(n\geq 63\)ならば\(n\)は\(\mathrm{(i),(ii)}\)を満たさない」という命題の証明を試みると:
\(n=7k~(k\geq 9)\)とおく.\(k=9\)とき,\(n=63\)より正の約数は\(1,3,7,9,21,63\)だから\((\mathrm{ii})\)を満たさない.\(k \geq 11\)のとき,\(7\)と\(k\)は\(n(=7k)\)の\(1\)でも\(n\)でもない正の約数だが,\[|k-2|=k-2\geq 11-2 =9\]となり\((\mathrm{ii})\)を満たさない.
これで\(2.\)の答えは\(35\)と\(49\)のみであることが分かりました。
\(\textbf{3}.\)
上と同じように考えれば,\(n\)が\(3\)の倍数のとき,\(5\)の倍数のときも同じように\(\mathrm{(i),(ii)}\)を満たす\(n\)が簡単に見つかる気がします。もしそうであれば,結局\(2,3,5,7\)の倍数についてはすべて調べ上げたことになるので,調べるべき残りの\(n\)は(\(\mathrm{(i)}\)より\(n\)は素数でないことに注意すれば)\(11\)以上の素因数からなる合成数のみ調べればよいことが分かります(エラトステネスのふるい)。また,その合成数の因数の個数に着目すれば,因数の個数が\(1\)個のとき素数になるから\(\mathrm{(i)}\)を満たさず,因数の個数が\(3\)個以上のときは最小でも\(11^{3}=1331\)となり\(1000\)を超えてしまうことから,(素)因数の個数は\(2\)個であることが分かります。さらに,\(37 \times 37 =1369>1000\)より,\(37\)以降の素数については考える必要はありません。以上の考察から以下のように結論できます:
\(n\)が\(3\)の倍数の場合
\(2,7\)の倍数のときはすでに調べてあり,また\(5\)の倍数の場合はこのあと調べるのでこれらを除いて調べると

求める\(n\)は\(9\)のみであることが分かる(証明は上と同様なので割愛).
\(n\)が\(5\)の倍数の場合

求める\(n\)は\(15\)と\(25\)のみであることが分かる(証明割愛).
あとは素因数が\(11\)以上で\(31\)以下であり,かつその個数が\(2\)個である合成数のみを調べればよい.

するとそれは(\(\mathrm{(ii)}\)に注意して)\[11^2,13^2,17^2,19^2,23^2,29^2,31^2,11\times13,17\times19,29\times 31\]すなわち\[121,169,289,361,529,841,961,143,323,899\]のみであることがわかる.以上により求める\(n\)は\[4,6,8,9,15,25,35,49,121,143,169,289,323,361,529,841,899,961\]となる.
(考え方終わり)
既知の解法にはまらないとき,あるいは既知の解法に帰着しないとき(=何をすればいいのか見通しが立たないとき),「とりあえず実験してみて,予想し,それを証明する」という姿勢はしばしば有効な気がします。(少なくとも泥臭く手を動かすだけで\(2.\)までは答えを導ける!)





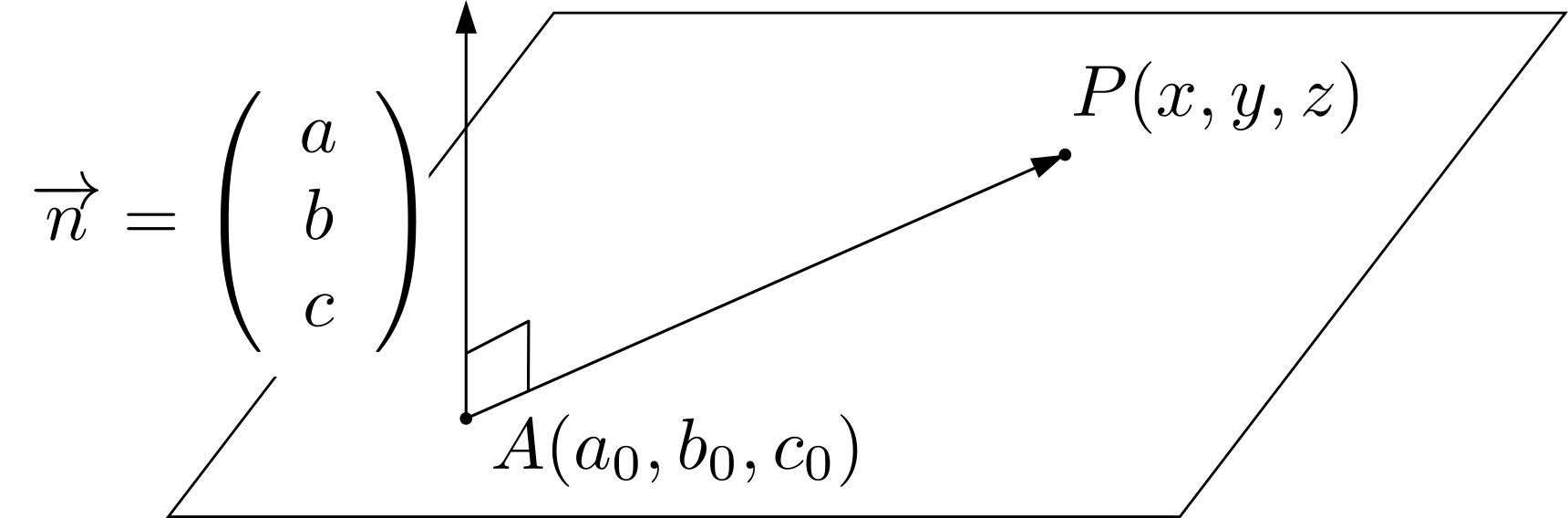 ここでは,平面はその平面の垂直方向とその平面が通る1点が定まれば決定することに着目します。平面の法線ベクトルを\(\overrightarrow{n}=(a,b,c)\),平面が通る1点の座標を\(A(a_0,b_0,c_0)\),平面上の任意の点を\(P(x,y,z)\)とおくことにします。\begin{align*}
ここでは,平面はその平面の垂直方向とその平面が通る1点が定まれば決定することに着目します。平面の法線ベクトルを\(\overrightarrow{n}=(a,b,c)\),平面が通る1点の座標を\(A(a_0,b_0,c_0)\),平面上の任意の点を\(P(x,y,z)\)とおくことにします。\begin{align*}